Scraper les tweets de nos politiques en python avec Twint
Besoin de récupérer des milliers de tweets en 5 lignes de code ?
Un seul mot : Twint !
Twint est une librairie python permettant de scraper des comptes ou des mots-clés sur Twitter. Plusieurs outils font déjà ce travail, alors quel est l’intérêt de cette librairie ? En deux mots :
- Utilisation sans inscription au préalable
- On ne passe par l’API Twitter. Il n’y a donc aucune limite dans la récupération du nombre de tweets !
Je vous renvoie vers leur github si vous désirez voir toutes les possibilités offertes par Twint : https://github.com/twintproject/twint
En guise de présentation, nous allons nous amuser à récupérer l’ensemble des tweets des politiques les plus médiatisés de notre cher pays.
Installation de Twint
Ici, rien de compliqué, on installe la librairie via pip :
pip3 install twint
Récupération des comptes Twitter
J’ai commencé par chercher une page internet recensant les comptes Twitter des politiques (histoire de ne pas m’amuser à chercher les comptes à la main). Je suis tombé sur ce site : http://ymobactus.miaouw.net/labo-top-politiques.php?mode=followers&liste=personnalites&tendance= , une ressource parfaite pour débuter notre travail !
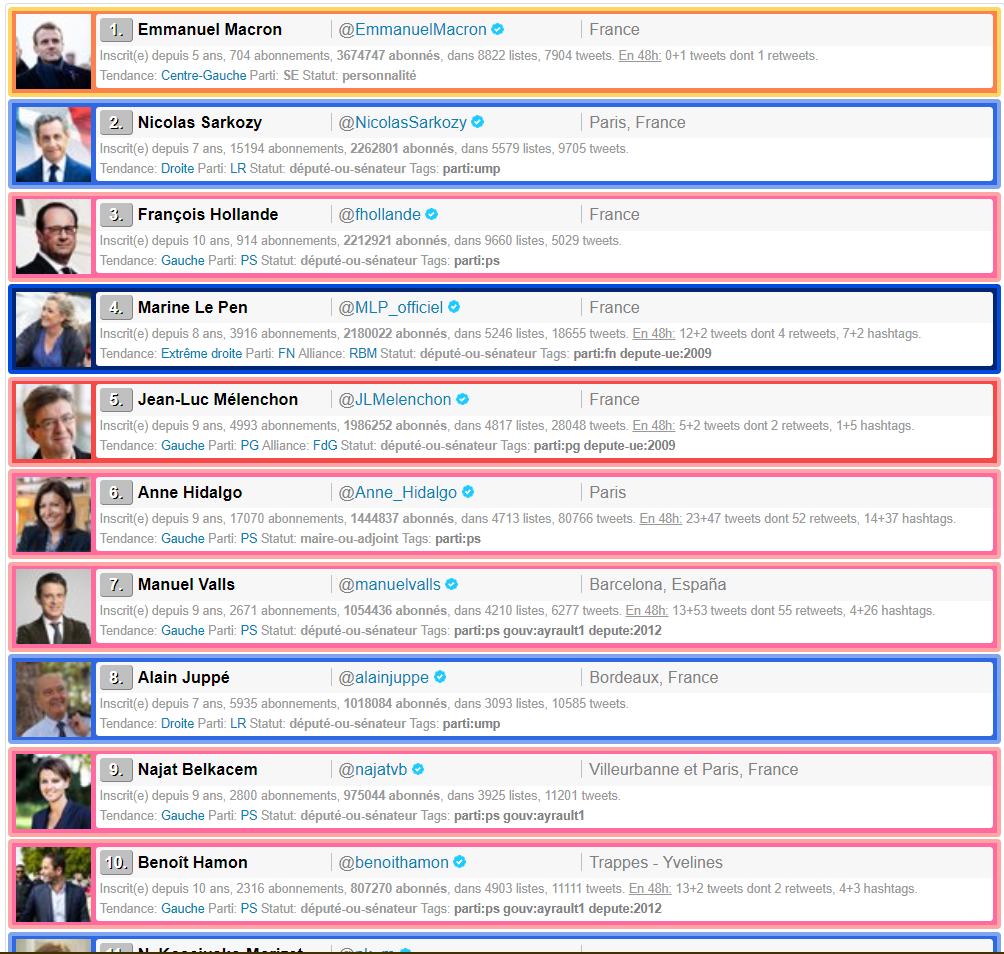
Pour scraper tous les noms des comptes Twitter, j’utilise la librairie BeautifulSoup.
En examinant le code html de la page, nous nous rendons compte que l’info que nous cherchons se situe dans la balise <a></a> :

Voici le morceau de code permettant de récupérer les liens urls :
#Déclaration de la liste des comptes
compte_twitter = []
stopwords = []
# Make the GET request to a url
r = requests.get('http://ymobactus.miaouw.net/labo-top-politiques.php?mode=followers&liste=personnalites&tendance=')
# Extract the content
d = r.content
# Create a soup object
soup = BeautifulSoup(d)
# Récupération du href contenant le lien url redirigeant vers le compte Twitter de chaque personnalité
handles = [ a["href"] for a in soup.find_all("a", href=True) if("twitter" in a["href"])]
# On boucle afin de ne récupérer que la fin de url (nom du compte)
for url in handles:
compte = re.search('[^/]+(?=/$|$)',url)
stopwords.append(compte.group().lower())
compte_twitter.append(compte.group())
En sortie, nous récupérons donc tous les urls de chaque compte, sous cette forme : https://twitter.com/EmmanuelMacron
Néanmoins, pour que la recherche Twint fonctionne, il nous faut uniquement le nom du compte. Un petit REGEX fera l’affaire :
for url in handles:
compte = re.search('[^/]+(?=/$|$)',url)
#Ajout des noms à la liste compte_twitter
compte_twitter.append(compte.group())
Et voici ce que nous récupérons en sortie :
compte_twitter = [‘lists’, ‘topolitiq’, ‘EmmanuelMacron’, ‘NicolasSarkozy’, ‘fhollande’, ‘MLP_officiel’, ‘JLMelenchon’, ‘Anne_Hidalgo’, ‘manuelvalls’, ‘alainjuppe’, ‘najatvb’, ‘benoithamon’, ‘nk_m’, ‘ChTaubira’, ‘RoyalSegolene’, ‘bayrou’, ‘fleurpellerin’, ‘FrancoisFillon’, ‘Lagarde’, ‘BrunoLeMaire’, ‘montebourg’, ‘CecileDuflot’, ‘EPhilippePM’, ‘jf_cope’, ‘laurentwauquiez’, ‘MarionMarechal’, ‘jeanmarcayrault’, ‘vpecresse’, ‘LaurentFabius’, ‘BGriveaux’, ‘BCazeneuve’, ‘pierremoscovici’, ‘nadine__morano’, ‘JLBorloo’, ‘dupontaignan’, ‘axellelemaire’, ‘GilbertCollard’, ‘f_philippot’, ‘aurelifil’, ‘CCastaner’, ‘jpraffarin’, ‘MarisolTouraine’, ‘MartineAubry’, ‘EvaJoly’, ‘cestrosi’, ‘gerardcollomb’, ‘xavierbertrand’, ‘PhilippePoutou’, ‘ECiotti’, ‘SLeFoll’, ‘datirachida’, ‘lepenjm’, ‘ymobactus’, ‘ymobactus’]
Twint, à toi de jouer !
C’est ici que Twint rentre en jeu ! En effet, nous allons désormais récupérer l’ensemble des tweets pour chaque item de notre liste compte_twitter :
for compte in compte_twitter:
#nom du fichier csv qui sera produit
filename = compte+".csv"
#lancement de l’objet twint
c = twint.Config()
#nom du compte que nous recherchons
c.Username = compte
#Nous désirons stocker un fichier csv contenant l’ensemble des tweets récupérés
c.Store_csv = True
# Nombre de tweets récupérés
c.Count = True
#Si nous avons déjà un fichier csv des tweets, nous n’analysons pas le compte Tweeter de la personnalité
if os.path.exists(filename):
print('déjà présent :' + compte )
#Sinon, nous récuperons la liste des tweets
else:
c.Custom["tweet"] = ["tweet"]
c.Output = filename
#Nous ne souhaitons pas voir les tweets apparaitre dans la console Python
c.Hide_output = True
#Nous ne récupérons pas les hashtags
c.Show_hashtags = False
c.Store_object = True # nous stockons également les tweets dans un objet
#Lancement de la recherche
twint.run.Search(c)
#Tous les tweets seront conservés dans la variable tweets_as_objects
tweets_as_objects = twint.output.tweets_object
Vous pouvez désormais laisser votre ordinateur de côté et vaquer à vos occupations car l’opération risque de durer un petit moment… Néanmoins, si vous regardez de temps en temps votre console Python, vous pourrez vous apercevoir que Twint récupère bien les tweets de nos chers camarades…

Voilà ! Après quelques heures de traitement, nous avons bien nos fichiers csv créés, chaque csv contenant l’ensemble des tweets de chaque politique présent dans notre liste !
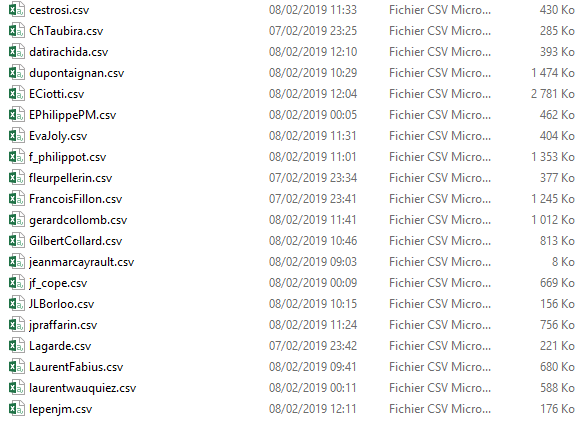
BONUS : observer les mots les plus utilisés par les politiques sur Twitter.
Voici un petit exercice d’utilisation de la donnée extraite via Twint. L’idée ici est d’observer les mots les plus fréquemment utilisés par chaque personnalité politique.
1. Suppression des “mots polluants”
Nous allons créer une liste contenant un PAQUET de petits mots de liaison, de déterminants, de conjonctions de coordination ainsi que les noms, prénoms et les noms des comptes de chaque personnalité. Nous souhaitons nettoyer et écrémer au maximum les occurrences qui seront relevées dans notre script, et ainsi éviter de se retrouver avec des listes remplies de ‘de’, ‘la’, ‘on’, ‘a’,’est’, etc…
Stopwords = ['personnes','dire','autres','lui','note','blog','monsieur','dai','via','seront','jour','car','instagr','suivez','veut','player','fortes','dire','mai','tour','cet','donner','dailymotion','actualites','grand','grande','encore','vive','video','bit','mettre','youtube','lui','cela','videos','frontnational','mlp','donnons','interview','toute','celui','retrouvez','parce','doivent','aura',"moments",'retrouvons','propose','souhaite','sarkozy','nicolas','pen','marine','html','revenu','generationsmvt','leurs','mois','leur','our','place','premier','ici','marche','construire','toujours','premier','facebook','chaque','vie','for''direct','macron',’sera','pscp','and','live','devons','the','entre','toutes','plan','belle', 'lefigaro', 'accueil', 'deux', 'serai','temps','soit','bravo','rien','aussi','visite','ceux','depuis', 'sans','trop','non','partir','votre','bien','sommes','ils','hier','tinyurl','soutien','quand','status','grand','nouvelle','jamais','avoir','rendez','face','mes','suis','veux','comme','contre','bourdindirect','fait','https','pays','aujourd',"notre","de","en","alpes","ladroitederetour","politique","elle","politique","leur","tout","ont","de","la","à","le","les","et","pour","aux","pic","des","com","en","un","pas","une","je","ce","a","est","sur","twitter","cette","hui","être","sont","faut","faire","il","ne","avec","au","qui","que","du","dans","plus","on","http","se","y","nous","mais","fr","son","ai","avons","notre","vous","nos","par","www","tous","merci","ses","fait","doit","soir","demain","matin","soir","très","ces","ans","mon"]
2. Calcul des occurrences les plus nombreuses pour chaque compte
Si le nombre de tweets présents dans le fichier est supérieur à deux, alors
on ouvre le fichier csv :
# Si Len de l'objet supérieur à 2 (car les deux premiers items de la list sont des comptes inexistants), alors on ouvre le fichier csv
if len(tweets_as_objects) > 2:
frequency = {}
p = {}
#ouverture du fichier csv
document_text = open(filename, 'r', encoding="utf8")
#nous lisons le fichier et tous les mots seront en minuscule
text_string = document_text.read().lower()
Nous procédons également à quelques modifications dans chaque fichier : le texte sera lu en minuscule, on ignorera les hashtags et les mentions @, ainsi que tous les mots présents dans notre liste des mots bannis :
#nous supprimons également tous les hashtags ou noms de compte cités dans les tweets
text_string = re.sub(r'(\A|\s)@(\w+)','',text_string)
text_string = re.sub(r'(\A|\s)#(\w+)','',text_string)
#on supprime chaque mot présent dans notre liste des mots bannis et apparaissant dans le fichier csv
regex = re.compile('|'.join(r'\b{}\b'.format(word) for word in stopwords))
Il ne nous reste plus qu’à boucler afin de trouver les occurrences les plus nombreuses présentes dans chacun des fichiers csv :
for mot in match_pattern:
#si le mot est present, on ne fait rien
if regex.match(mot):
p = mot
#s’il n’est pas present dans la liste, alors on regarde s’il est composé de plus de 2 charactères. Si oui, on l’ajoute dans notre objet frequency.
else:
if len(mot) > 2:
count = frequency.get(mot,0)
frequency[mot] = count + 1
txt_name = compte+'_occurrence.txt'
print(txt_name)
print(Counter(frequency).most_common(50))
Le résultat est savoureux ! Voyez par vous-même :
François Fillon :
[(‘france’, 1262), (‘ump’, 609), (‘projet’, 393), (‘europe’, 288), (‘militants’, 286), (‘national’, 234), (‘gouvernement’, 217), (‘travail’, 214), (‘redressement’, 206), (‘droite’, 204), (‘moi’, 188), (’emploi’, 187), (‘etat’, 184), (‘gauche’, 174), (‘besoin’, 170), (‘candidat’, 167), (‘francois’, 163), (‘campagne’, 158), (‘pouvoir’, 154)]
Emmanuel Macron :
[(‘france’, 902), (‘europe’, 562), (‘projet’, 236), (‘monde’, 218), (‘ensemble’, 202), (‘travail’, 196), (‘avenir’, 172), (‘femmes’, 139), (‘besoin’, 127), (‘histoire’, 125), (‘engagement’, 113), (‘terrorisme’, 112), (’emploi’, 108), (‘confiance’, 103), (‘chacun’, 102)]
Gilbert Collard :
[(‘france’, 528), (‘loi’, 163), (‘migrants’, 155), (‘passage’, 137), (‘ministre’, 133), (‘saint’, 131), (‘gauche’, 129), (‘gouvernement’, 129), (‘medias’, 125), (‘justice’, 113), (‘mots’, 109), (‘droit’, 107), (‘policiers’, 105), (‘question’, 103), (‘mort’, 92), (‘police’, 92), (‘pourquoi’, 91), (‘europe’, 91), (‘terrorisme’, 88), (‘homme’, 86)]
Laurent Wauquier :
[(‘france’, 429), (’emploi’, 257), (‘droite’, 233), (‘europe’, 178), (‘auvergne’, 117), (‘travail’, 114), (‘entreprises’, 107), (‘valeurs’, 91), (‘gouvernement’, 90), (‘jeunes’, 81), (‘famille’, 76), (‘immigration’, 74), (‘taxes’, 67), (‘monde’, 61), (‘classes’, 59), (‘militants’, 59), (‘moyennes’, 58), (‘questions’, 57), (‘pouvoir’, 57), (‘droit’, 57)]
Christiane Taubira :
[(‘monde’, 123), (‘justice’, 112), (‘gauche’, 74), (‘droit’, 61), (‘enfants’, 58), (‘france’, 52), (‘victimes’, 48), (‘loi’, 47), (‘femmes’, 46), (‘voix’, 41), (‘rencontre’, 40), (‘avenir’, 39), (‘etat’, 34), (‘jeunes’, 33), (‘esprit’, 33), (‘droits’, 32), (‘ensemble’, 30), (‘travail’, 29), (‘courage’, 28), (‘valeurs’, 28), (‘histoire’, 28)]
Vous en voulez encore ?! Un petit quiz est disponible ici !