How to scrape data from Twitter Using python and Twint
Do you need to scrap a thousand of tweets in a few lines of code ?
One word : Twint !
Twint is a really nice and simple python library for scraping Twitter account or keywords. There are a lot of python modules that can do this task, so what are the benefits of using Twint ? Two pros :
- Can be used anonymously and without Twitter sign up
- No rate limitations
Take of look at TwintProject github for more informations : https://github.com/twintproject/twint
As a presentation to this incredible module, we are going to get all tweets of some famous french politicians and analyze which words are the most commonly used by each of them.
Installation of Twint
Nothing complicated here, we are using pip for installing Twint:
pip3 install twint
Get a list of the most famous french politicians and scrap all their account names on Twitter
In order to automate the process, I looked for a webpage where all the Twitter accounts were gathered. Fortunately, I discovered this website: http://ymobactus.miaouw.net/labo-top-politiques.php?mode=followers&liste=personnalites&tendance= , a prefect ressource for starting our work !
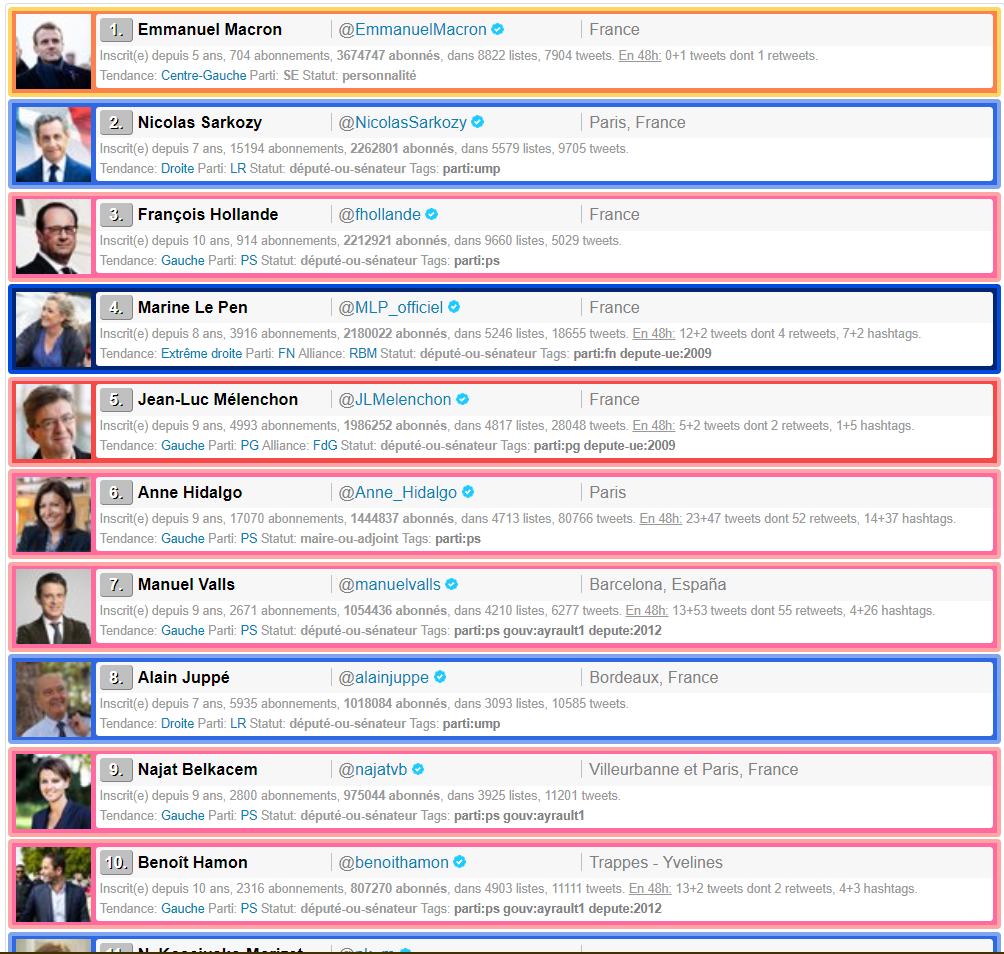
For scraping all the Twitter name accounts, I used the python library BeautifulSoup.
By examining closely the HTML code of the website, we can see that the information we need can be found inside <a></a> tag :

This is the little piece of code I used for scraping all the urls :
#Déclaration de la liste des comptes
compte_twitter = []
stopwords = []
# Make the GET request to a url
r = requests.get('http://ymobactus.miaouw.net/labo-top-politiques.php?mode=followers&liste=personnalites&tendance=')
# Extract the content
d = r.content
# Create a soup object
soup = BeautifulSoup(d)
# Récupération du href contenant le lien url redirigeant vers le compte Twitter de chaque personnalité
handles = [ a["href"] for a in soup.find_all("a", href=True) if("twitter" in a["href"])]
# On boucle afin de ne récupérer que la fin de url (nom du compte)
for url in handles:
compte = re.search('[^/]+(?=/$|$)',url)
stopwords.append(compte.group().lower())
compte_twitter.append(compte.group())
In output, we have all the url links contained in a list, in this form : https://twitter.com/EmmanuelMacron
However, we only need the Twitter name accounts in order to scrap all the tweets of each politician. A little REGEX can to the trick :
for url in handles:
compte = re.search('[^/]+(?=/$|$)',url)
#Ajout des noms à la liste compte_twitter
compte_twitter.append(compte.group())
In output, we get this list :
compte_twitter = [‘lists’, ‘topolitiq’, ‘EmmanuelMacron’, ‘NicolasSarkozy’, ‘fhollande’, ‘MLP_officiel’, ‘JLMelenchon’, ‘Anne_Hidalgo’, ‘manuelvalls’, ‘alainjuppe’, ‘najatvb’, ‘benoithamon’, ‘nk_m’, ‘ChTaubira’, ‘RoyalSegolene’, ‘bayrou’, ‘fleurpellerin’, ‘FrancoisFillon’, ‘Lagarde’, ‘BrunoLeMaire’, ‘montebourg’, ‘CecileDuflot’, ‘EPhilippePM’, ‘jf_cope’, ‘laurentwauquiez’, ‘MarionMarechal’, ‘jeanmarcayrault’, ‘vpecresse’, ‘LaurentFabius’, ‘BGriveaux’, ‘BCazeneuve’, ‘pierremoscovici’, ‘nadine__morano’, ‘JLBorloo’, ‘dupontaignan’, ‘axellelemaire’, ‘GilbertCollard’, ‘f_philippot’, ‘aurelifil’, ‘CCastaner’, ‘jpraffarin’, ‘MarisolTouraine’, ‘MartineAubry’, ‘EvaJoly’, ‘cestrosi’, ‘gerardcollomb’, ‘xavierbertrand’, ‘PhilippePoutou’, ‘ECiotti’, ‘SLeFoll’, ‘datirachida’, ‘lepenjm’, ‘ymobactus’, ‘ymobactus’]
Twint, it’s up to you !
Now we are using Twint for scraping all the tweets of our dear friends contained inside our list compte_twitter :
for compte in compte_twitter:
#nom du fichier csv qui sera produit
filename = compte+".csv"
#lancement de l’objet twint
c = twint.Config()
#nom du compte que nous recherchons
c.Username = compte
#Nous désirons stocker un fichier csv contenant l’ensemble des tweets récupérés
c.Store_csv = True
# Nombre de tweets récupérés
c.Count = True
#Si nous avons déjà un fichier csv des tweets, nous n’analysons pas le compte Tweeter de la personnalité
if os.path.exists(filename):
print('déjà présent :' + compte )
#Sinon, nous récuperons la liste des tweets
else:
c.Custom["tweet"] = ["tweet"]
c.Output = filename
#Nous ne souhaitons pas voir les tweets apparaitre dans la console Python
c.Hide_output = True
#Nous ne récupérons pas les hashtags
c.Show_hashtags = False
c.Store_object = True # nous stockons également les tweets dans un objet
#Lancement de la recherche
twint.run.Search(c)
#Tous les tweets seront conservés dans la variable tweets_as_objects
tweets_as_objects = twint.output.tweets_object
Now you can go outside and get some air because it may take a while to achieve the taskt… However, if you take a look to the console, you might be able to see Twint collecting successfully some tweets…

Voilà ! After few hours of processing, a bunch of .csv files have been created, each file containing hundreds of tweets !
BONUS : analyze the words most used by each politician on Twitter.
Here is a little case of what can we do with this amount of data. The idea here, is to analize the words most used by each politician on Twitter.
1. Delete all the “polluting words”
We are going to create a list containing A LOT of little french little words (like of, who, we, is, have…) in order to clear our dataset.
Stopwords = ['personnes','dire','autres','lui','note','blog','monsieur','dai','via','seront','jour','car','instagr','suivez','veut','player','fortes','dire','mai','tour','cet','donner','dailymotion','actualites','grand','grande','encore','vive','video','bit','mettre','youtube','lui','cela','videos','frontnational','mlp','donnons','interview','toute','celui','retrouvez','parce','doivent','aura',"moments",'retrouvons','propose','souhaite','sarkozy','nicolas','pen','marine','html','revenu','generationsmvt','leurs','mois','leur','our','place','premier','ici','marche','construire','toujours','premier','facebook','chaque','vie','for''direct','macron',’sera','pscp','and','live','devons','the','entre','toutes','plan','belle', 'lefigaro', 'accueil', 'deux', 'serai','temps','soit','bravo','rien','aussi','visite','ceux','depuis', 'sans','trop','non','partir','votre','bien','sommes','ils','hier','tinyurl','soutien','quand','status','grand','nouvelle','jamais','avoir','rendez','face','mes','suis','veux','comme','contre','bourdindirect','fait','https','pays','aujourd',"notre","de","en","alpes","ladroitederetour","politique","elle","politique","leur","tout","ont","de","la","à","le","les","et","pour","aux","pic","des","com","en","un","pas","une","je","ce","a","est","sur","twitter","cette","hui","être","sont","faut","faire","il","ne","avec","au","qui","que","du","dans","plus","on","http","se","y","nous","mais","fr","son","ai","avons","notre","vous","nos","par","www","tous","merci","ses","fait","doit","soir","demain","matin","soir","très","ces","ans","mon"]
2. Calculate the most numerous occurrences of each Twitter account
Now, in each .csv files, we are going to count the number of tweets. If this number of tweets is highter than 2 (because later when I’ve scraped Twitter URLs, we’ve collected URL which were not Twitter accounts), we will open the file :
# Si Len de l'objet supérieur à 2 (car les deux premiers items de la list sont des comptes inexistants), alors on ouvre le fichier csv
if len(tweets_as_objects) > 2:
frequency = {}
p = {}
#ouverture du fichier csv
document_text = open(filename, 'r', encoding="utf8")
#nous lisons le fichier et tous les mots seront en minuscule
text_string = document_text.read().lower()
Next, we modificate some things to our .csv files : the text will be convert in lower case, we’re going to ignore hashtags and mentions, and also we are going to delete all words who will match with our words present in the “polluting words” list:
#nous supprimons également tous les hashtags ou noms de compte cités dans les tweets
text_string = re.sub(r'(\A|\s)@(\w+)','',text_string)
text_string = re.sub(r'(\A|\s)#(\w+)','',text_string)
#on supprime chaque mot présent dans notre liste des mots bannis et apparaissant dans le fichier csv
regex = re.compile('|'.join(r'\b{}\b'.format(word) for word in stopwords))
The last step is to create a loop for finding all the most numerous occurrences of each politician :
for mot in match_pattern:
#si le mot est present, on ne fait rien
if regex.match(mot):
p = mot
#s’il n’est pas present dans la liste, alors on regarde s’il est composé de plus de 2 charactères. Si oui, on l’ajoute dans notre objet frequency.
else:
if len(mot) > 2:
count = frequency.get(mot,0)
frequency[mot] = count + 1
txt_name = compte+'_occurrence.txt'
print(txt_name)
print(Counter(frequency).most_common(50))
And TADAAAAA ! If you understand french, the result is very tasteful :
François Fillon :
[(‘france’, 1262), (‘ump’, 609), (‘projet’, 393), (‘europe’, 288), (‘militants’, 286), (‘national’, 234), (‘gouvernement’, 217), (‘travail’, 214), (‘redressement’, 206), (‘droite’, 204), (‘moi’, 188), (’emploi’, 187), (‘etat’, 184), (‘gauche’, 174), (‘besoin’, 170), (‘candidat’, 167), (‘francois’, 163), (‘campagne’, 158), (‘pouvoir’, 154)]
Emmanuel Macron :
[(‘france’, 902), (‘europe’, 562), (‘projet’, 236), (‘monde’, 218), (‘ensemble’, 202), (‘travail’, 196), (‘avenir’, 172), (‘femmes’, 139), (‘besoin’, 127), (‘histoire’, 125), (‘engagement’, 113), (‘terrorisme’, 112), (’emploi’, 108), (‘confiance’, 103), (‘chacun’, 102)]
Gilbert Collard :
[(‘france’, 528), (‘loi’, 163), (‘migrants’, 155), (‘passage’, 137), (‘ministre’, 133), (‘saint’, 131), (‘gauche’, 129), (‘gouvernement’, 129), (‘medias’, 125), (‘justice’, 113), (‘mots’, 109), (‘droit’, 107), (‘policiers’, 105), (‘question’, 103), (‘mort’, 92), (‘police’, 92), (‘pourquoi’, 91), (‘europe’, 91), (‘terrorisme’, 88), (‘homme’, 86)]
Laurent Wauquier :
[(‘france’, 429), (’emploi’, 257), (‘droite’, 233), (‘europe’, 178), (‘auvergne’, 117), (‘travail’, 114), (‘entreprises’, 107), (‘valeurs’, 91), (‘gouvernement’, 90), (‘jeunes’, 81), (‘famille’, 76), (‘immigration’, 74), (‘taxes’, 67), (‘monde’, 61), (‘classes’, 59), (‘militants’, 59), (‘moyennes’, 58), (‘questions’, 57), (‘pouvoir’, 57), (‘droit’, 57)]
Christiane Taubira :
[(‘monde’, 123), (‘justice’, 112), (‘gauche’, 74), (‘droit’, 61), (‘enfants’, 58), (‘france’, 52), (‘victimes’, 48), (‘loi’, 47), (‘femmes’, 46), (‘voix’, 41), (‘rencontre’, 40), (‘avenir’, 39), (‘etat’, 34), (‘jeunes’, 33), (‘esprit’, 33), (‘droits’, 32), (‘ensemble’, 30), (‘travail’, 29), (‘courage’, 28), (‘valeurs’, 28), (‘histoire’, 28)]
Super utile, merci 🙂
It works really well for me