Une plongée dans les dessous du Hackaviz 2019

Il y a une semaine se déroulait la remise des prix du Hackaviz 2019. Pour l’occasion, j’ai décidé de revenir sur les principales étapes du processus de création de ma réalisation. Cet article n’a absolument pas la prétention d’être un guide, j’y partage juste quelques points qui m’ont permis d’aboutir à ma contribution finale ! Si vous ne l’avez pas vu, direction : https://tonyhauck.com/dataviz/story.html
Le hackaviz, kesako ?!
Le hackaviz est un concours de datavisualisation organisé par l’association Toulouse-Dataviz. Il s’est déroulé entre le 21 et le 31 mars 2019.
Votre mission, si toutefois vous l’acceptez…
Seul ou en équipe, l’objectif est de raconter une histoire sous forme de graphiques à partir d’un jeu de données imposé et dans un temps limité.
Jeu de données pour ce hackaviz 2019 ?
Les organisateurs nous avaient préparé deux jeux de données relatifs aux déplacements professionnels en Occitanie :
Par commune :
Pour chaque commune (4516 lignes / 43 colonnes) :
- Données générales sur la commune
- Flux d’actifs interne, vers d’autres communes de travail, depuis d’autres communes de domicile.
- Données agrégés sur le mode de transport et les catégories socio-professionnelles
- Données géographiques de la commune
Par trajet :
Pour chaque couple commune domicile – commune de travail (1912 lignes / 23 colonnes) :
- Données générales sur la commune
- Nombre d’actifs qui vont d’une commune à une autre pour le travail
- Données de distance et de durée de trajets entre les deux communes
- Données géographiques des communes domicile et travail
Les outils ?
Tout ce que vous souhaitez ! Du binôme papier-crayon à la tablette graphique, vous êtes totalement libre.
Let’s go !
Pour bien commencer, il était vital de me prévoir une petite sélection de sons. D’expérience, je sais que pour réussir à tirer quelque chose de mon cerveau, je dois le stimuler avec des BO de films :
J’ai découpé la suite de l’article sur les dessous de mon Hackaviz en 3 temps :
- Exploration
- Visualisation
- Structuration
1 – EXPLORATION de la donnée : avancer à tâtons pour trouver une histoire à raconter
Je trouve que c’est à la fois l’étape la plus intéressante et la plus frustrante. Intéressante car on malaxe notre donnée, on la pétrit dans tous les sens, on la travaille afin d’en extraire son essence. Mais c’est également une étape frustrante car le temps file et on a l’impression de ne pas avancer assez vite, de pédaler dans un bac de semoules (de semoules, oui).
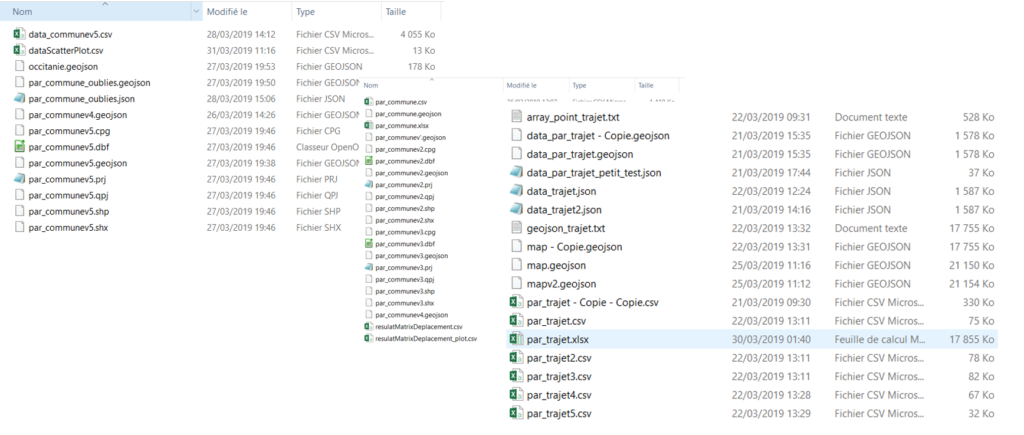
Au cours de cette étape, j’ai principalement utilisé Excel et Qgis. Excel pour révéler les phénomènes statistiques et Qgis pour les transposer sur un plan spatial. De fait, ma formation de géographe et de géomaticien me pousse inexorablement à toujours mettre mes variables statistiques à l’épreuve des cartes. Cela me permet de rattacher des chiffres au réel et à me demander s’il n’y a pas d’explications géographiques derrière des phénomènes statistiques. Même si je manipule R et Python, je reviens très souvent à Excel pour la génération de graphiques. En effet, en quelques clics on arrive à distinguer si nous sommes sur la bonne voie avec notre échantillon de données, si les données nous parlent et si des phénomènes intéressants émergent de notre gloubi-boulga de chiffres.
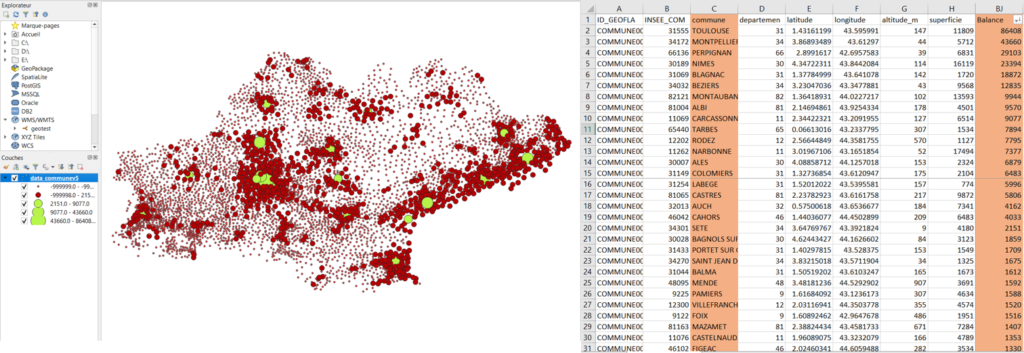
Quelques jours plus tard, mon exploration et mes tâtonnements ont porté leurs fruits ! J’ai relevé quelques points chauds qui pourront structurer mon analyse, parmi lesquels :
- Les déplacements professionnels s’organisent selon deux espaces (Toulouse et le littoral).
- Le prolongement de la diagonale du vide français est visible en Occitanie.
- Les déplacements se polarisent autour de plusieurs centres concentrant les activités économiques, la population…
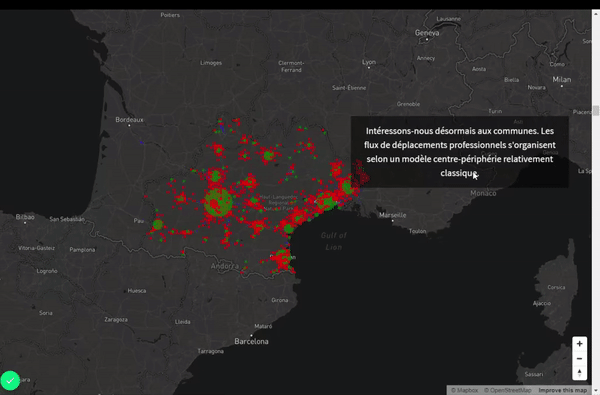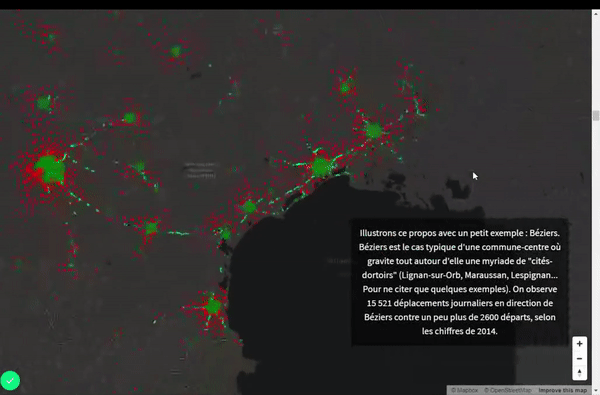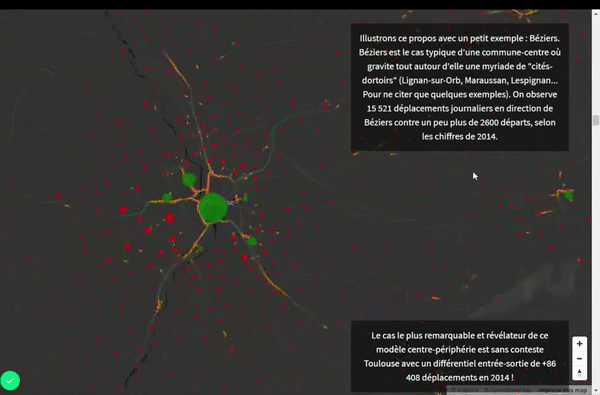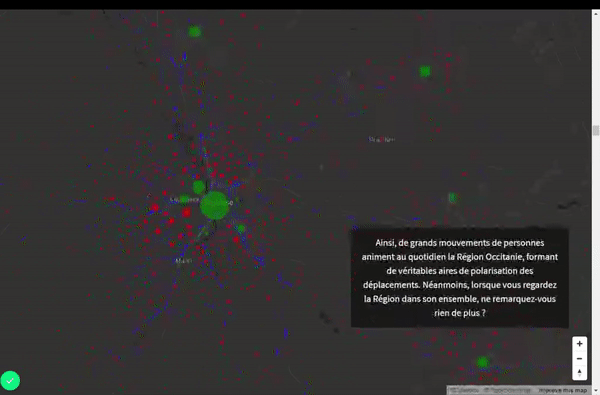
- Omniprésence de la catégorie des ouvriers dans les cités-dortoirs du littoral, bilan contrasté dans l’espace toulousain.
De plus, en parallèle du listing de mes points chauds, j’ai commencé à imaginer des visualisations possibles pour chacun d’entre eux ainsi qu’un ordre et une structuration possible. Ici, rien de tel que le binôme crayon-cahier pour mettre en place ses idées !
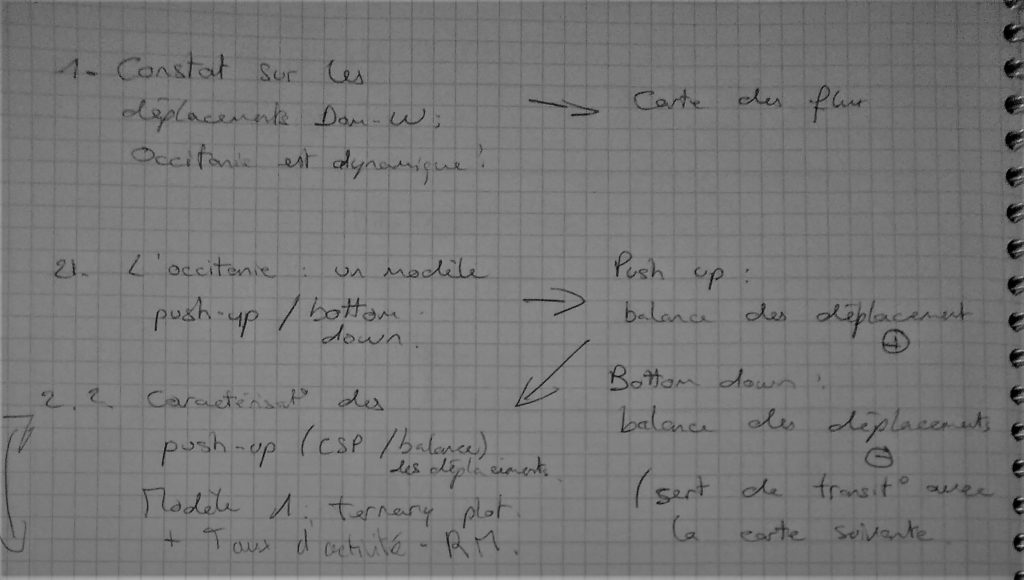
Cette structure a été amené à évoluer au fil de mes réflexions, de mes découvertes… Et du temps qui me restait 😉
2 – VISUALISATION de mon histoire : le choix des armes
Donner du liant à mon récit avec Scrollama
En m’inscrivant à ce concours, ma motivation principale était d’apprendre de nouvelles choses, monter en compétences sur des outils inconnus pour moi.
Biberonné aux histoires interactives du New York Times, du Washington Post ou du journal Les Echos (cocorico), j’avais comme objectif d’utiliser une bibliothèque de scrollytelling. Le scrollytelling est la contraction des mots scroll et storytelling, autrement dit : dérouler une histoire. En associant une gestuelle addictive à la lecture, la narration devient immersive et engageante. Un article parut sur Pudding.cool en liste quelques-unes : https://pudding.cool/process/how-to-implement-scrollytelling/demo/scrollstory/
Il me fallait un outil simple et rapide à prendre en main au vu du peu de temps dont je disposais pour écrire mon histoire. J’ai donc jeté mon dévolu sur Scrollama : https://russellgoldenberg.github.io/scrollama/
J’ai l’outil qui formera le liant entre chacune des parties de mon récit. Attaquons maintenant le cœur de notre narration : le développement des datavisualisations !
Les datavisualisations
J’ai décidé que chaque chapitre de mon histoire devait être jalonné de graphiques. J’ai souhaité ajouter de l’interactivité à mes dataviz afin de garder le lecteur en éveil et à le pousser à jouer avec mes datavisualisations. Il devait être acteur de mon récit. Pour le développement, j’ai principalement utilisé :
- D3.js, une librairie javascript qui permet de mettre en place de chouettes visualisations, mais qui demande un temps de développement beaucoup plus important que l’utilisation de librairies plus simples comme C3.js ou highchart.js.
Pour chaque visualisation, je m’inspire de travaux piochés ici et là sur les internets. Trouver de l’inspiration est un point central dans le développement d’une dataviz ! La communauté D3 est très active et il est “facile” d’adapter des exemples de création en libre accès (https://github.com/d3/d3/wiki/Gallery) dans ses propres projets.
Oui, ça peut paraître “facile” vu comme ça. Mais développer des datavisualisation sous D3.js peut très rapidement devenir une véritable prise de tête ! On peut très vite perdre 2 à 3 heures uniquement pour placer correctement des marges (toi même tu sais, développeur D3.js…). Je ne parle même pas du travail esthétique, visuel et technique permettant d’aboutir à un résultat convenable et fonctionnel. Néanmoins, lorsque ma donnée prend vie graphiquement pour la première fois, je saute de joie comme un gamin !

- Mapbox pour les cartes interactives. Je travaille très souvent avec cet outil, je connais ces capacités, je prévoyais d’intégrer un peu de 3D (si le temps me le permettait) et de travailler avec des tuiles vectorielles (dans le but d’accélérer les temps d’affichage des nombreuses entités géographiques qui allaient être affichées à l’écran !)
les tuiles vectorielles sont des paquets de données géographiques, regroupés dans des “tuiles” prédéfinies de forme grossièrement carrée pour un transfert sur le Web.
Wikipedia
Comme pour les graphiques, j’ai assemblé des morceaux de diverses dataviz trouvées sur internet. Par exemple, la carte des flux a été inspiré, entre autre, par deux travaux repérés sur Twitter et reddit :
J’ai également utilisé le calculateur d’itinéraire de Mapbox pour récupérer l’ensemble des trajets pour tous les déplacements domicile-travail. J’ai écrit un petit script Python qui réalise cette opération et qui concatène les traces dans un geojson.
3 – STRUCTURATION de mon récit et articulations
Besoin d’une accroche visuelle
Je voulais que mon récit débute avec quelque chose de fort et de clinquant. Je souhaitais une dataviz épurée, sans statistique, sans chiffre, quelque chose d’impactant afin d’amener progressivement le lecteur vers ma première interrogation. Ma carte des flux devait jouer ce rôle. J’ai donc utilisé un gradient de couleurs assez flashy et une vitesse d’animation relativement élevée pour attirer l’œil du lecteur (sans pour autant lui déclencher une crise d’épilepsie) !
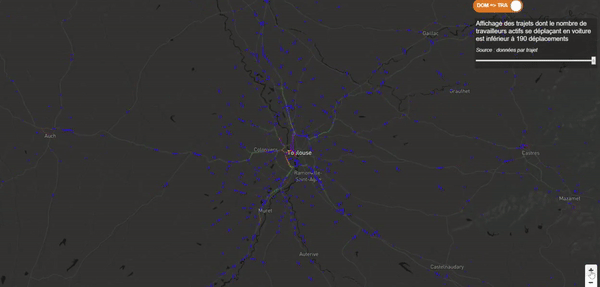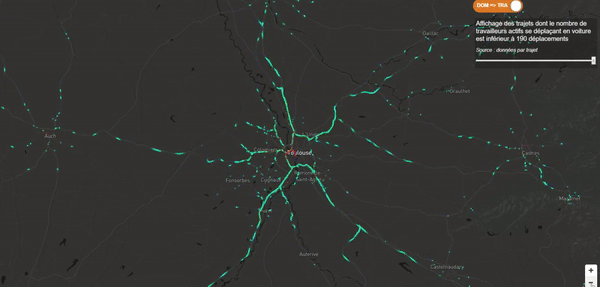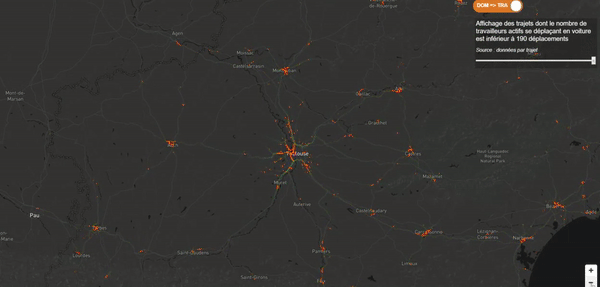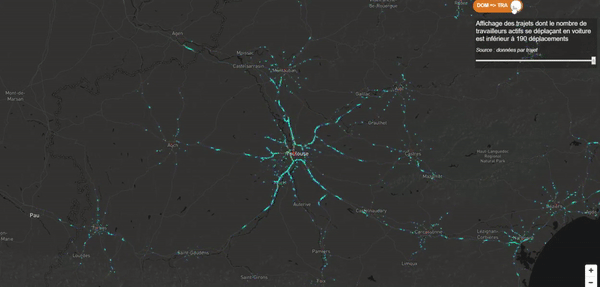
Jouer avec les triggers
Scrollama permet de mettre en place des triggers liés à la position de l’utilisateur sur la page web. Par exemple, lorsque l’utilisateur scrollera à un point donné du récit, un trigger se déclenchera, entraînant un événement particulier défini dans mon code javascript (zoom sur un point donné de la carte, rechargement d’un graphique selon un nouveau jeu de données…). J’ai énormément joué sur la gestion de ces triggers pour garder l’attention du lecteur et pour le diriger vers les points chauds de l’histoire que je tentais de lui raconter.
Interrogation => Visualisation => Réponses => Interrogation => Visualisation => Réponses
Enfin, il fallait que chaque visualisation soit en mesure de servir un propos et une idée, chaque idée devant rebondir sur une interrogation qui elle-même donnera lieu à une datavisualisation, et ainsi de suite… J’ai tenté de respecter ce schéma tout au long de ma réalisation.
La tête dans le guidon
Dans ce genre d’exercice, on a souvent la tête dans le guidon. On se presse pour espérer terminer dans le temps imparti. C’est pourtant important de prendre de la distance sur ce que l’on est en train de produire. Pour accomplir cette tâche, rien de tel que l’aide d’un œil neuf pour aborder son projet sous un nouvel angle ! Dans mon cas, j’ai grandement amélioré la structure narrative de mon histoire (en me débarrassant des fioritures et autres lourdeurs du récit venant polluer mes idées directrices) et ça a même fait émergé des interrogations que je n’avais pas eu l’occasion de voir…
Que conclure ?
Au travers de cet article, j’ai souhaité vous présenter rapidement diverses étapes par lesquelles je suis passé pour aboutir à ma contribution finale.
C’était une première tentative d’utilisation d’une bibliothèque de scrollytelling. J’ai peut être gagné un prix pour ma contribution, mais celle-ci n’en reste pas moins perfectible ! En effet, dans un laps de temps aussi court, j’ai dû faire des choix, mettre des idées de côté, raccourcir ma réalisation et ne pas m’attarder sur les détails. Sauf que les détails comptent et ils me sautent à la figure dès que je pose mon regard sur mon travail ! Il y aurait plusieurs modifications à apporter, je pense en vrac : aux différentes optimisations qu’il faudrait implémenter pour améliorer la rapidité d’exécution de mon script ; rendre ma page web responsive ; proposer une véritable analyse environnementale et écologique des flux domicile-travail (comme j’ai pu l’observer dans plusieurs contributions !).
Je tiens encore à remercier les participants et les organisateurs du HACKAVIZ car c’était vraiment une chouette expérience ! J’ai appris énormément de choses et plus important encore : ce concours m’a donné l’opportunité de remettre les mains dans le domaine de la datavisualisation… Et quel plaisir !
Quelques liens utiles :
Pour terminer, je vous pose quelques ressources intéressantes :
- Adobe Color Wheel
- The Big List of D3.js Examples de Christophe Viau
- Exemples Mapbox
- Deux extensions très utiles en développement : colorZilla (récupération du code couleur sur une page web) et Whatfont (pour connaître le font utilisé sur une page web)
- Dataviz project : Quel graphique utiliser selon la situation ?
- Un site interessant pour débuter en visualisation de données (leaflet, D3, Mapbox) : https://www.datavis.fr/